itea.regression
Interaction Transformation Evolutionary Algorithm for regression
This sub-module implements a specialization of the base classes BaseITEA
and BaseITExpr to be used on regression tasks.
Ideally, the user should import and use only the ITEA_regressor
implementation, while the ITExpr_regressor should be created by means of the
itea instead of manually by the user.
The ITExpr_regressor works just like any fitted scikit regressor,
but — in order to avoid the creation of problematic expressions — I
strongly discourage the direct instantiation of ITExpr_regressor.
Sub-module contents:
ITEA_regressor
For a more detailed description of the arguments, check the BaseITEA documentation.
- class itea.regression.ITEA_regressor(*, gens=100, popsize=100, tfuncs={'id': <function ITEA_regressor.<lambda>>}, tfuncs_dx=None, expolim=(-2, 2), max_terms=5, fitness_f=None, simplify_method=None, random_state=None, verbose=None, labels=[], **kwargs)[source]
Bases:
BaseITEA,RegressorMixinThis is the implementation of the ITEA for the regression task.
The expressions will have their coefficients adjusted by means of the scikit’s linearRegression method. The fitness will be measured using the RMSE metric (smaller is better).
Notice that this method does not have the
estimator_kwas there is in theITEA_classifier.Constructor method.
- Parameters
gens (int, default=100) – number of generations of the evolutionary process.
popsize (int, default=100) – population size, consistent through each generation.
expolim (tuple (int, int), default = (-2, 2)) – tuple specifying the bounds of exponents for ITExpr.
max_terms (int, default=5) – the max number of IT terms allowed.
fitness_f (string or None, default='rmse') – String with the method to evaluate the fitness of the expressions. Can be one of
['rmse', 'mse', 'r2']. If none is given, then the rmse function will be used.simplify_method (string or None, default=None) –
String with the name of the simplification method to be used before fitting expressions through the evolutionary process. When set to None, the simplification step is disabled.
Simplification can impact performance. To be simplified, the expression must be previously fitted. After the simplification, if the expression was changed, it should be fitted again to better adjust the coefficients and intercept to the new IT expressions’ structure.
random_state (int, None or numpy.random_state, default=None) – int or numpy random state. When None, a random state instance will be created and used.
verbose (int, None or False, default=None) – When verbose is None, False or 0, the algorithm will not print information. If verbose is an integer
n, then everyngenerations the algorithm will print the status of the generation. If verbose is set to -1, every generation will print information.labels (list of strings, default=[]) – (
ITExprparameter) list containing the labels of the data that will be used in the evolutionary process, and will be used inITExprconstructors.tfuncs (dict, default={'id': lambda x: x}) – (
ITExprparameter) transformations functions. Should always be a dict where the keys are the names of the transformation functions and the values are unary vectorized functions.tfuncs_dx (dict, default=None) – (ITExpr_explainer parameter) derivatives of the given transformations functions, the same scheme. When set to None, the itea package will use automatic differentiation through jax to create the derivatives.
- bestsol_
an ITExpr expression used as it is (linear combination of IT terms).
- Type
- fitness_
fitness (RMSE) of the final expression.
- Type
float
- convergence_
two nested dictionaries. The outer have the keys
['fitness', 'n_terms', 'complexity'], and the inner have['min', 'mean', 'std', 'max']. Each value of the inner dictionary (for example itea.convergence_[‘fitness’][‘min’]) is a list, containing the information of every generation. This dictionary can be used to inspect information about the convergence of the evolutionary process. The calculations are made filtering infinity values.- Type
dict
- exectime_
time (in seconds) the evolutionary process took.
- Type
int
- fit(X, y)[source]
Performs the evolutionary process.
- Parameters
X (array-like of shape (n_samples, n_features)) – training data. Should be a matrix of float values.
y (array-like of shape (n_samples, )) – expected values.
- Returns
self – itea after performing the evolution. Only after fitting the model that the attributes
bestsol_andfitness_will be available.- Return type
- Raises
ValueError – If one or more arguments would result in an invalid execution of itea.
ITExpr_regressor
For a more detailed description of the arguments, check the BaseITExpr documentation.
- class itea.regression.ITExpr_regressor(*, expr, tfuncs, labels=[], fitness_f=None, **kwargs)[source]
Bases:
BaseITExpr,RegressorMixinITExpr for the regression task. This will be the class in
ITEA_regressor.bestsol_.Constructor method.
- Parameters
expr (list of Tuple[Transformation, Interaction]) – list of IT terms to create an IT expression. It must be a python built-in list.
tfuncs (dict) – should always be a dict where the keys are the names of the transformation functions and the values are unary vectorized functions (for example, numpy functions). For user-defined functions, see numpy.vectorize for more information on how to vectorize your transformation functions.
labels (list of strings, default=[]) – list containing the labels of the variables that will be used. When the list of labels is empty, the variables are named
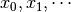 .
.fitness_f (string or None, default=None) – String with the method to evaluate the fitness of the expressions. Can be one of
['rmse', 'mse', 'r2']. If none is given, then ‘rmse’ is used as default fitness function for the regression task. Raises ValueError if the attribute value is not correct.
- n_terms
the number of inferred IT terms.
- Type
int
- is_fitted
boolean variable indicating if the ITExpr was fitted before.
- Type
bool
- _fitness
fitness (RMSE) of the expression on the training data.
- Type
float
- intercept_
regression intercept.
- Type
float
- coef_
coefficients for each term.
- Type
numpy.array of shape (n_terms, )
- covariance_matrix(X, y)[source]
Estimation of the covariance matrix of the coefficients.
- Parameters
X (numpy.array of shape (n_samples, n_features)) –
- Returns
covar – covariance matrix of the coefficients.
The last row/column is the intercept.
- Return type
numpy.array of shape (n_terms+1, n_terms+1)
- fit(X, y)[source]
Fits the linear model created by combining the IT terms.
This method performs the transformation of the original data in X to the IT expression domain then fits a linear regression model to calculate the best coefficients and intercept to the IT expression.
If the expression fails to fit, its
_fitnessis set to np.inf, since the fitness function is the RMSE and smaller values are better.- Parameters
X (array-like of shape (n_samples, n_features)) – training data.
y (array-like of shape (n_samples, )) – expected values.
- Returns
self – itexpr after fitting the coefficients and intercept. Only after fitting the model that the attributes
coef_andintercept_will be available.- Return type
Notes
This fit method does not check if the input is consistent, to minimize the overhead since the
ITEA_regressorwill work with a population ofITExpr_regressorinstances. The input is then checked in the fit method fromITEA_regressor. If you want to use the fit method directly from theITExpr_regressor, it is recommended that you do the check withcheck_array` `that scikit-learn provides in ``sklearn.utils.validation.
- predict(X)[source]
Predicts the response value for each sample in X.
If the expression fails to predict a finite value, then the default returned value is the expression’s intercept.
- Parameters
X (array-like of shape (n_samples, n_features)) – samples to be predicted. Must be a two-dimensional array.
- Returns
p – predicted response value for each sample.
- Return type
numpy.array of shape (n_samples, )
- Raises
NotFittedError – If the expression was not fitted before calling this method.